
www.industrieweb.fr
09
'22
Written on Modified on
Nouvelle gamme de transformeurs compatibles IPU par Graphcore et Hugging Face
Graphcore et Hugging Face proposent désormais un nombre plus important de modalités et tâches dans la bibliothèque open source Hugging Face Optimum dédiée à l’optimisation des performances. Les développeurs disposent d’une vaste gamme de modèles de transformeurs Hugging Face prêts à l’emploi et optimisés pour fournir les meilleures performances possibles sur les IPU Graphcore.
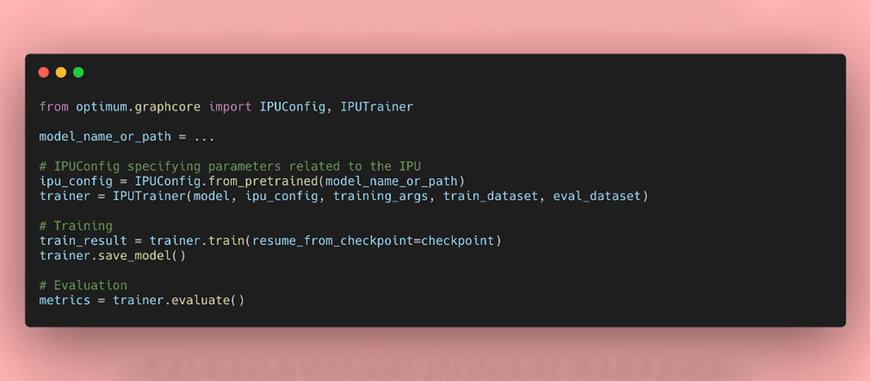
En plus du modèle de transformeur BERT disponible depuis le lancement d’Optimum Graphcore, les développeurs ont accès à neuf modèles prenant en charge le traitement automatique des langues, la vision industrielle et la reconnaissance vocale. Ils sont fournis avec des fichiers configuration IPU et des paramètres ajustés, pré-entraînés et prêts à l’emploi.
Nouveaux modèles Optimum
Vision industrielle
Le ViT (Vision Transformer) constitue une avancée de taille en termes de reconnaissance des images et utilise le mécanisme du transformateur comme composant principal. Ainsi, lorsque des images sont chargées dans ViT, elles sont divisées en plus petites unités, de la même manière qu’avec les mots dans les système de traitement linguistiques. Chaque unité est ensuite encodée par le transformeur (on appelle cela l’intégration) pour être traitée individuellement.
Traitement automatique des langues
Le GPT-2 (Generative Pre-trained Transformer 2) est un modèle de transformeur de création de texte pré-entraîné sur un très grand corpus de données anglophones, de manière auto-régulée. Cela veut dire que le modèle est pré-entraîné uniquement sur du texte brut, à l’aide d’un processus automatique de génération d’entrées et d’étiquettes, sans qu’aucun humain ne soit intervenu (d’où l’utilisation de données publiques). Il est entraîné pour générer des textes en devinant le mot suivant dans une phrase donnée.
Le RoBERTa (Robustly optimized BERT approach) est un modèle de transformeur pré-entraîné sur un large corpus de données anglophones, de manière auto-régulée (comme le GPT-2). Ce modèle a été pré-entraîné avec l’objectif MLM (Masked Language Modeling). Pour une phrase donnée, il masque aléatoirement 15 % des mots fournis, puis exécute la phrase entière masquée afin de deviner les mots dissimulés. RoBERTa peut donc être utilisé pour la modélisation du langage masqué (MLM), mais il a surtout été pensé pour être ajusté à la précision dans le cadre de tâches en aval.
Le DeBERTa (Decoding-enhanced BERT with disentangled attention) est un modèle neuronal de langage pré-entraîné pour les tâches de traitement automatique des langues. Il met à jour les modèles 2018 BERT et 2019 RoBERTa à l’aide de deux techniques novatrices, à savoir un mécanisme d’attention démêlée et un décodeur de masque amélioré, optimisant ainsi considérablement l’efficacité du pré-entraînement et les performances des tâches en aval.
Le BART est un modèle encodeur-encodeur de transformeur (seq2seq) doté d’un encodeur bidirectionnel (BERT) et d’un décodeur autorégressif (GPT). BART est pré-entraîné en (1) corrompant le texte avec une fonction de bruit arbitraire, et en (2) apprenant un modèle permettant de reconstruire le texte d’origine. Le modèle BART s’avère particulièrement efficace lorsqu’ajusté pour la génération de texte (par exemple, dans le cadre d’un récapitulatif, d’une traduction, etc.), mais aussi pour les tâches de compréhension (classification, réponse aux questions, etc.).
Le LXMERT (Learning Cross-Modality Encoder Representations from Transformers) est un modèle de transformeur multimodal permettant d’apprendre des représentations de langue et une vision. Il dispose de trois encodeurs : encodeur de relations d’objets, encodeur de langue et encodeur intermodalité. Il est pré-entraîné à l’aide d’une combinaison de MLM, de Visual-Language Text Alignment, de ROI-Feature Regression, de Masked Visual-Attribute Modeling, de Masked Visual-Object Modeling et de Visual-Question Answering Objectives. Ce modèle a atteint des résultats optimaux sur les ensembles de données Visual-Question-Answering CQA et VQA.
Le T5 (Text-to-Text Transfer Transformer) est un nouveau modèle révolutionnaire capable de convertir n’importe quel texte dans un format compatible avec l’apprentissage automatique pour la traduction, la réponse aux questions ou la classification. Il propose un cadre homogène permettant de convertir les problèmes textuels dans un format texte à texte. Ainsi, les même modèles, fonctions d’objectif, hyperparamètres et procédures de décodage peuvent être réutilisés dans le cadre de tâches diverses liées au traitement automatique des langues.
Reconnaissance vocale
Le HuBERT (Hidden-Unit BERT) est un modèle auto-régulé de reconnaissance vocale et pré-entraîné avec des données audio. Son apprentissage consiste en un modèle de langue/acoustique sur entrées continues. Le modèle HuBERT est aussi voire plus performant que le wav2vec 2.0 exécuté dans les corpus Librispeech (960 h) et Libri-light (60 000 h) avec les sous-ensembles de 10 min, 1 h, 10 h, 100 h et 960 h.
Le Wav2Vec2 est un modèle de reconnaissance vocale pré-entraîné et auto-régulé. Grâce à un objectif de pré-entraînement contrastif novateur, Wav2Vec2 est capable d’apprendre des représentations vocales pratiques à partir d’un immense ensemble de données sans étiquettes, puis d’être ajusté sur la base de quelques données retranscrites. Il s’avère ainsi plus puissant et conceptuellement plus simple.
Hugging Face Optimum Graphcore : l’avenir d’un partenariat fructueux
Graphcore est devenu membre fondateur du Hugging Face Hardware Partner Program en 2021. Les deux entreprises avaient pour but de rendre l’innovation plus facile dans le domaine de l’intelligence artificielle.
Depuis, Graphcore et Hugging Face ont travaillé d’arrache-pied pour simplifier et accélérer l’entraînement des modèles de transformeurs sur IPU. Le premier modèle Optimum Graphcore (BERT) est sorti l’an dernier.
Les transformeurs se sont révélés être extrêmement efficaces avec nombre de fonctions, et notamment l’extraction, la génération de texte, l’analyse des sentiments, la traduction, et bien plus encore. Les modèles comme le BERT sont couramment utilisés par les clients de Graphcore, dans des situations variées telles que la cybersécurité, l’automatisation des appels vocaux, la découverte de médicaments et la traduction.
L’optimisation de leurs performances nécessite un temps, des efforts et une expertise considérables, auxquels beaucoup d’entreprises et d’organisations ne pouvaient pas faire face. Grâce à Hugging Face et à sa bibliothèque open source de modèles de transformeurs, ces problèmes sont de l’histoire ancienne. L’intégration des IPU à Hugging Face permet également aux développeurs de tirer parti des modèles, ainsi que des ensembles de données disponibles dans le Hub de Hugging Face.
Les développeurs peuvent désormais compter sur les systèmes Graphcore pour entraîner dix types de modèles de transformeurs de pointe et accéder à des milliers d’ensembles de données avec peu de codage. Ce partenariat permet aux utilisateurs de bénéficier d’outils et d’un écosystème pour le téléchargement et l’ajustement de modèles de pointe pré-entraînés, adaptés à de nombreux domaines et tâches.
Tirer parti des derniers équipements et logiciels de Graphcore
Si les utilisateurs toujours plus nombreux de Hugging Face profitaient déjà des avantages en termes de vitesse, de performances et de coûts offerts par la technologie IPU, l’ajout des derniers équipements et logiciels Graphcore en date n’aura pour effet que de décupler ces améliorations.
En ce qui concerne les équipements, le Bow IPU (annoncé en mars et désormais en cours de livraison) est le premier processeur au monde à utiliser la technologie d’empilement Wafer-on-Wafer (WoW) 3D, propulsant les performances déjà reconnues de l’IPU vers de nouveaux horizons. Chaque Bow IPU propose des avancées révolutionnaires en architecture de calcul et en implémentation, en communication, et en mémoire. Cet IPU offre jusqu’à 350 téraFLOPS de calcul d’IA (soit 40 % plus performant) et jusqu’à 16 % d’efficacité énergétique en plus comparé à la génération précédente. Cela ne requérant aucun codage, les utilisateurs de Hugging Face Optimum peuvent basculer librement entre des IPU d’ancienne génération et des processeurs Bow.
Les logiciels jouant également un rôle crucial, Optimum propose une expérience plug-and-play grâce au kit SDK Poplar de Graphcore facile à utiliser (lui aussi mis à jour à sa version 2.5). Poplar simplifie l’entraînement de modèles de pointe sur les équipements les plus avancés grâce à une intégration complète aux environnements d’apprentissage automatique standard (notamment PyTorch, PyTorch Lightning et TensorFlow) et à des outils de déploiement et d’orchestration comme Docker et Kubernetes. Poplar étant compatible avec ces systèmes tiers, largement répandus, les développeurs peuvent sans difficulté transposer des modèles provenant d’autres plateformes de calcul et, ainsi, bénéficier pleinement des fonctionnalités d’IA avancées de l’IPU.
Premiers pas avec les modèles Optimum Graphcore de Hugging Face
Si vous souhaitez profiter à la fois des avantages de la technologie IPU et des modèles de transformeurs, téléchargez la dernière gamme de modèles Optimum Graphcore sur le site web de Hugging Face, ou accédez au code via le référentiel Optimum de Hugging Face dans GitHub.
En outre, Graphcore met à disposition une page de ressources pour développeurs, qui comprend notamment l’IPU Model Garden (un référentiel d’applications ML prêtes à être déployées : vision industrielle, traitement automatique des langues, réseaux graphiques, etc.), ainsi que des documents, des didacticiels, des vidéos explicatives, des webinaires, et plus encore. Cette page donne également accès au référentiel GitHub de Graphcore et à la liste complète de modèles Hugging Face Optimum.
www.graphcore.ai
